About the project
The purpose of the WebData project is to build a national research infrastructure for internet data. The infrastructure will provide access for researchers, students, and other interested parties, while personal data and copyright legislation are taken into account. The project is funded by the Research Council of Norway.
WebData will facilitate research on Norwegian and Sámi language and culture, and support the development of language technology for these languages. This includes creating web corpora for Bokmål, Nynorsk, and Sámi which can be used in large language models. The project also aims to investigate the representation of Sámi language and culture in harvested web resources, contributing to the preservation of and research on Sámi cultural heritage.
WebData will also enable research on how the Norwegian public sphere has been shaped by the transition to the internet. It will make possible studies of elections, democracy, media, freedom of expression, and potential threats to democratic institutions.
Project Objectives
The WebData project has four main goals. During the project period (2025–29) we will:
- build a research platform for searching, exploring, and retrieving data
- automatically classify and clean texts containing (sensitive) personal data
- annotate data in order to provide analytical services (e.g. event extraction, sentiment analysis, analysis of language development)
- develop the infrastructure in close collaboration with the research community through needs and representation studies
Project Organization
The National Library of Norway leads the project. The project has partners with expertise in language technology and machine learning: the Norwegian Computing Center (NR), the University of Oslo (the Language Technology Group and HumIT), and Giellatekno – the Centre for Sámi Language Technology at UiT The Arctic University of Norway.
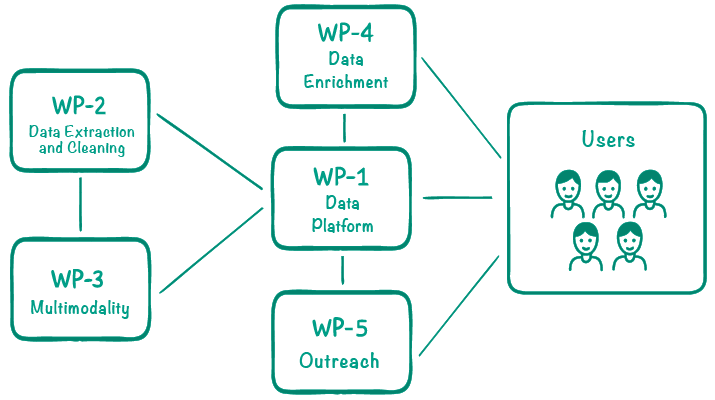
Work Packages
The project is organised into five work packages (WP):
- WP-1: Data platform will develop a web-based service with a user interface as the entry point to the web archive.
- WP-2: Data extraction and cleaning will build software to extract, clean, and categorize text data from downloaded web pages.
- WP-3: Multimodality will develop methods for extracting and searching data that is not text, e.g. audio and (moving) images.
- WP-4: Data enrichment aims to annotate a selection of web texts for use in language technology, e.g. to enable search for names and events.
- WP-5: Outreach & Dissemination is responsible for contact with the research communities that will use the platform, ensuring that the platform meets researchers’ needs and that Sámi language is well represented in the harvesting.